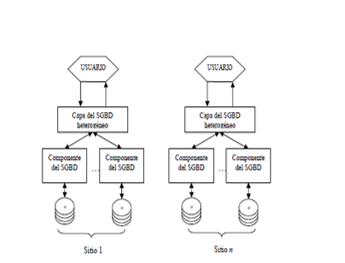
Los tipos de heterogeneidades en los sistemas de bases de datos pueden ser clasificadas
en
- las debidas a las
diferencias en el SGBD
- las debidas a las
diferencias en la semántica de los datos.
La heterogeneidad
debida a la utilización de diversos SGBDs es común e organizaciones que crecen
sin una planificación en cuanto a sus sistemas de información. Dichos sistemas
evolucionan paulatinamente en diferentes SGBDs o diferentes modelos de
conceptualización tales como: jerárquico, de red, relacional u orientado a
objetos. Diferentes departamentos dentro de la empresa pueden tener requerimientos
diferentes y pueden seleccionar diferentes SGBDs. También los SGBDs adquiridos
a lo largo de un período de tiempo pueden ser diferentes debido a los cambios
en la tecnología. Cada SGBD tiene un modelo de datos subyacente utilizado para
definir estructuras de datos y las restricciones. Tanto los aspectos de
representación (estructura y restricciones) como de lenguaje pueden dar lugar a
la heterogeneidad.
Diferencias en la
estructura:
Diferentes modelos de
datos proporcionan diferentes primitivas estructurales. Pueden darse cuatro
tipos de conflictos: de tipo, de dependencia, de clave o de comportamiento.
Los conflictos de tipo
se producen cuando el mismo objeto es representado por un atributo en un
esquema y por una entidad en otro.
Los problemas de
dependencia se Diseñó y Construcción de Bases de Datos Distribuidas
Heterogéneas sobre Oracle Y SQL Server
producen cuando los
distintos modos de relación (por ejemplo, una relación uno a uno frente a una
de muchos a muchos) se usan para representar lo mismo en diferentes esquemas.
Los conflictos de clave se producen cuando existen varias claves candidatas disponibles
y se seleccionan claves primarias diferentes en distintos esquemas. Los
conflictos de
comportamiento están implícitos en los mecanismos de modelado. Por ejemplo,
borrar el último elemento de una BD puede provocar la eliminación de la entidad
que contiene (es decir, la eliminación del último empleado puede causar la
disolución del departamento). Si el contenido de la información no es el mismo,
puede ser muy difícil solventar las diferencias.
Diferencias en las
restricciones:
Dos modelos de datos
pueden soportar diferentes restricciones. Esto quiere decir que puede ser que
en un modelo de datos existan x tipos de restricciones y en otro modelo y,
que posiblemente sean diferentes. Los disparadores (o algún otro mecanismo)
deben ser utilizados en los sistemas relacionales para captar la semántica de
estos.
Diferencias en los
lenguajes de consulta:
Como por ejemplo cuando
se utilizan diferentes lenguajes de consulta para manipula los datos
representados en modelos de datos diferentes. Incluso cuando dos SGBDs se basan
en el mismo modelo de datos, las diferencias en los lenguajes de consulta (por ejemplo,
Quel1 y SQL) o las diferentes versiones de SQL soportado por dos SGBDs relacionales
pueden contribuir a la heterogeneidad.
Heterogeneidades debido a
diferencias semánticas
La heterogeneidad
semántica es un término bastante cargado, sin una definición clara. Básicamente
se refiere a las diferencias entre las BBDD que se relacionan con el significado,
la interpretación y el uso previsto de los datos. Sin duda, los aspectos más importantes
de la heterogeneidad semántica se revelan como conflictos de nombres. El
problema fundamental de
nombres es el de los sinónimos y los homónimos. Dos entidades idénticas que
tienen diferentes nombres son sinónimos, y dos entidades diferentes que tienen
nombres idénticos son homónimas. La detección de la heterogeneidad semántica es
un problema difícil. Normalmente, los esquemas de los SGBD no proporcionan la
semántica suficiente para interpretar los datos de forma coherente. La
heterogeneidad debida a diferencias en los modelos de
datos también
contribuye a la dificultad en la identificación y resolución de la heterogeneidad
semántica. También es difícil descomponer la heterogeneidad debida a diferencias
en el SGBD de los resultantes de la heterogeneidad semántica
Bibliografia:
Laura Martínez M.. (2010). Ventajas de las BBDD en sistemas heterogéneos. Diseño y Construcción de BD Distribuidas Heterogéneas sobre Oracle y SQLSERVER(39). Madrid: Santillas.