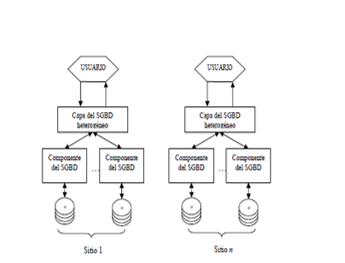
La fragmentación es un conjunto de técnicas para
dividir la BD en unidades lógicas, llamadas fragmentos, cuyo almacenamiento
puede asignarse a los diversos sitios. Estas técnicas se utilizan durante el
proceso de diseño de BDD. La información concerniente a la fragmentación de los
datos se almacena en un catálogo global del sistema al que tiene acceso el
software cliente cuando es necesario.
La fragmentación es un concepto que surge en los
modelos que incluyen algún tipo de particionado y tiene implicaciones físicas y
lógicas.
•
Fragmento lógico:
Bloque de datos localizado en algún SGBDD que puede ser descrito (en términos
relacionales) como el resultado de una proyección y/o una selección de la
información contenida en la BD, de modo que resulten subconjuntos disjuntos de
ella. Por tanto, una vez que la BD ha sido dividida en un conjunto de
fragmentos, todos los datos aparecen en uno y sólo uno de estos fragmentos
•
Fragmento físico: Subconjunto de un fragmento
lógico que se almacena completo en un nodo. Cada uno de los fragmentos físicos
de un fragmento lógico se localizan en uno o más nodos dependiendo del modelo
de distribución de los datos.
El esquema de fragmentación es el conjunto de las
distintas relaciones que se han obtenido del ELG y las condiciones empleadas
para esta división expresado en algebra relacional.
Existen distintas formas de fragmentar una relación:
Fragmentación
vertical
Fragmentación
horizontal
Fragmentación
mixta
Razones
para la fragmentación
Los esquemas de fragmentación se diseñan teniendo en
cuenta el uso que se va a hacer de los datos que se almacenan en cada una de
las sedes, construyendo relaciones más pequeñas y más adaptadas a las
operaciones de recuperación y actualización que utilizan las aplicaciones,
tratando así de aligerar las comunicaciones entre los nodos debido al alto
coste que éstas tienen.
Las cuatro razones para la fragmentación son las
siguientes:
Es útil ya
que las aplicaciones de BD suelen funcionar con vistas, y por ello se pueden
utilizar distintas relaciones en distintos nodos para formar la unidad
distribuida.
Se consigue
una mayor eficiencia dado que los datos suelen estar almacenados cerca del nodo
que más utiliza dichos datos.
Permite
aumentar el grado de concurrencia porque la fragmentación de las relaciones
permite que una transacción pueda dividirse en subconsultas que operan sobre
estos fragmentos.
Aporta una
mayor seguridad, dado que los datos no utilizados por un nodo local no se
almacenan en él y por lo tanto no están al alcance para personas sin
autorización.
Si las aplicaciones tienen requisitos conflictivos
que impiden la descomposición de la relación en fragmentos mutuamente
exclusivos, estas aplicaciones cuyas vistas se definen en más de un fragmento
pueden sufrir una degradación del rendimiento.
El segundo problema está relacionado con el control
semántico de los datos, especialmente para el control de integridad. Como
resultado de la fragmentación, los atributos que participan en una dependencia
pueden ser descompuestos en diferentes fragmentos que pueden ser asignados a
diferentes sitios. En este caso, incluso la simple tarea de comprobar las
dependencias daría lugar a la búsqueda de los datos en diferentes sitios.
Requisitos
de información
Uno de los aspectos del diseño de distribución es
que contribuyen demasiados factores para conseguir un diseño óptimo. La
organización lógica de la base de datos, la ubicación de las aplicaciones, las
características de las solicitudes de acceso a la base de datos, y las
propiedades de los sistemas informáticos en cada sitio tienen influencia sobre
las decisiones de distribución. Esto hace que sea muy complicado para formular
un problema de distribución.
La información necesaria para el diseño de la
distribución puede dividirse en cuatro categorías: información de la base de
datos, la aplicación de la información, información de la red de comunicación,
y sistema informático
Reglas
de fragmentación
Hay que tener en cuenta que la fragmentación podría
afectar al rendimiento del SGBDD, especialmente cuando se utilizan distintos
fragmentos ubicados en distintos nodos para construir una vista. También el
control de la semántica de los datos puede ser más complicado por la
fragmentación.
Para asegurar que la BD no sufrirá cambios
semánticos durante la fragmentación de los datos, se definen las siguientes
tres normas que determinen la calidad de la fragmentación de una relación :
Completitud: Sea R una relación descompuesta en fragmentos F(R)
= {R1, R2,…, Rn}. Entonces cada atributo de la relación deberá encontrarse en
al menos uno de los fragmentos Ri asegurando así que no hay pérdida de
información.
Reconstrucción: si una relación R se descomponen en fragmentos de
la forma R1, R2,.., Rn, debería ser posible definir un operador relacional ∇ tal que R = ∇ Ri para todo Ri
є FR (Fragmentos de R).
El operador ∇ será diferente
para cada forma de fragmentación; sin embargo es importante poder
identificarlo. Esta regla asegura que las restricciones de integridad
referencial están resguardadas.
Disyunción: si una relación R es fragmentada horizontalmente
en R1, R2,…, Rn, y el dato di está en Rj y solo en Rj. Esta regla asegura que
los fragmentos son disjuntos. Si se trata de una fragmentación vertical, sólo
los atributos clave deben estar repetidos en todos los fragmentos, de modo que
la propiedad disyunción se refiere únicamente a los restantes atributos
Fragmentación
vertical
La fragmentación vertical divide la relación
verticalmente en columnas, así cada fragmento mantiene ciertos atributos de la
relación original [2]. La fragmentación
se realiza mediante la operación PROYECCIÓN: ∏Li (R) donde i= 1...n y Ri es el
conjunto de fragmentos en que se divide la relación original. Li es el criterio
de fragmentación.
Para que la fragmentación vertical sea correcta los
subconjuntos de atributos Li han de cumplir:
·
La unión de todos los
Li contiene todos los atributos de la relación original.
·
La intersección de
todos los Li consiste en la clave primaria de la relación original. Todos los
Li tienen en común la clave primaria para poder reconstruir R mediante JOIN.

Suponiendo que en el campus de Getafe hubiera un
nodo de la BD y otro nodo se ubicara en el campus de Leganés, y que por ejemplo
el tratamiento y consulta de los datos personales se hiciera en el primer
campus y el concerniente a los datos académicos se hiciera en el segundo,
podría ser interesante realizar una fragmentación vertical en la que por un
lado estuvieran: - los datos personales con los campos “Nombre”, “Apellidos” y
“Edad” (L1). - y otra de datos académicos con los campos “Campus”, “Titulación”
y “Cursos” (L2).
Así, se podría almacenar una subrelación (fragmento)
en el campus de Getafe y otra en el campus de Leganés, quedando cada
subrelación de la siguiente manera:
Fragmentación
horizontal
La fragmentación horizontal divide la relación en
subconjuntos de tuplas, cada uno de ellos con un significado lógico.
La fragmentación se realiza mediante la operación
SELECCIÓN: σ Ci (R) Existen dos tipos de
fragmentación horizontal: primaria y derivada. En la Ilustración 3 se puede
observar un esquema de la fragmentación horizontal y en Ejemplo 2 un caso de
fragmentación horizontal de una tabla. - Primaria, es una selección de la
relación original. La fragmentación se
realiza mediante la operación Ri = σPi (R) donde Pi es un predicado sobre uno o
más atributos de R y es la condición empleada para seleccionar el contenido de
los fragmentos.
- Derivada, es una selección en función de
predicados definidos sobre atributos de otras relaciones o fragmentos; esto se
debe a que la relación R a fragmentar depende de la relación Q. Además, R hace
referencia a Q mediante una clave
ajena. La fragmentación se realiza mediante la
operación Ri = R Qi donde Qi corresponde al conjunto de
fragmentos en los que se ha dividido la relación Q.
Qi donde Qi corresponde al conjunto de
fragmentos en los que se ha dividido la relación Q.
La semicombinacion ( )
se hace por el atributo que relacionan estas dos tablas.
Para que la fragmentación
horizontal sea correcta se tiene que cumplir que: La unión de todos los Ri sea la relación
original (R). La intersección de todos
los Ri sea vacía. La relación original se recupera mediante UNION de los
fragmentos.

Podría ser interesante realizar una fragmentación
horizontal por el campo “Campus” y almacenar cada fragmento en cada uno de los
campus, suponiendo que en estos hubiera un nodo de la BD, quedando cada
subrelación de la siguiente manera:
ALUMNOS_LEG: Fragmento correspondiente a alumnos del
campus de Leganés (R1 = σ (CAMPUS =
Leganés))
Fragmentación
mixta o híbrida
La fragmentación mixta es la mezcla de fragmentación
horizontal y vertical. Hay dos tipos de fragmentación mixta
·
Fragmentación VH Es
una fragmentación vertical seguida de una fragmentación horizontal, sobre cada
uno de los fragmentos verticales.
Ejemplo 3 fragmentación vertical-horizontal
En la
siguiente relación ALUMNOS (R)
Podría ser interesante realizar una fragmentación
vertical en la que se particionaran - los datos personales con los campos
“Nombre”, “Apellidos” y “Edad” (FV1) - los datos académicos con los campos
“Campus”, “Titulación” y “Cursos” (FV2) Seguida de una fragmentación horizontal
por el campo “Campus”.
De este modo se obtendrían los siguientes
fragmentos…. Datos personales (FV1) del
Campus Leganés (FV1H1), Campus Getafe (FV1H2) y Campus Colmenarejo (FV1H3) y datos académicos (FV2) del Campus Leganés (FV2H1), Campus
Getafe (FV2H2) y Campus Colmenarejo (FV2H3).
- ·
Fragmentación HV Es
una fragmentación horizontal seguida de una fragmentaciónvertical, sobre cada
uno de los fragmentos horizontales.

En la relación ALUMNOS podría ser interesante
realizar una fragmentación vertical por el campo “Campus” Campus de Leganés (FH1) Campus de Getafe
(FH2) Campus de Colmenarejo (FH3)
Seguida de una fragmentación vertical (V1) en la que
por un lado estuvieran - los datos
personales con los campos “Nombre”, “Apellidos” y “Edad” (campus de Leganés FH1V1, campus Getafe FH2V1
y campus Colmenarejo FH3V1) - y otra
(V2) de datos académicos con los campos “Campus”, “Titulación” y “Cursos”
(campus de Leganés FH1V2, campus Getafe FH2V2 y
campus Colmenarejo FH3V2).
bibliografia: Laura Martínez Martín. (2010). Alternativas de replicación. En Diseño y construción de base de datos distribuidas(21-28). México: Santillas.